云原生大数据架构中实时计算维表与结果表的选型实践 数据处理与存储服务视角
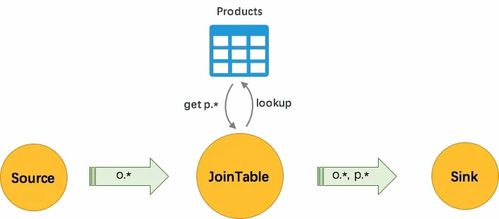
在云原生大数据架构中,实时计算已成为驱动业务决策、实现即时响应的核心引擎。其中,维表(Dimension Table)与结果表(Result Table)的选型,直接决定了实时数据处理的性能、成本与可维护性。本文将从数据处理和存储服务的视角,探讨这两类关键表的选型实践。
一、 维表选型:快速、稳定的数据关联基石
维表通常用于实时流计算中的数据关联(如流表JOIN),提供静态或准静态的上下文信息(如用户画像、商品信息)。其选型需兼顾查询性能、数据更新机制与云原生服务的集成度。
- 云原生数据库服务:如 Amazon Aurora、Google Cloud Spanner 或 阿里云 PolarDB。这些服务提供高可用、强一致性与毫秒级查询延迟,适合维表数据规模适中(如千万级以内)、更新频率较低但要求强一致性的场景。通过内置的读写分离与自动扩展能力,能有效支撑实时计算的高并发点查。
- 分布式缓存/内存数据库:如 Redis(云托管服务如 Amazon ElastiCache、阿里云 Tair)或 Apache Ignite。当维表数据量不大(如百万级),但对关联查询的延迟要求极高(亚毫秒级)时,此类服务是首选。它们将维表全量或热点数据常驻内存,通过KV接口提供极致性能。需注意缓存更新策略(如TTL、旁路缓存更新)与数据一致性的平衡。
- 云原生宽表数据库:如 Google Bigtable、Amazon DynamoDB 或 HBase on Cloud。适用于维表数据规模巨大(十亿级以上)、模式灵活且需按主键或前缀范围高效查询的场景。它们擅长高吞吐、低延迟的随机读写,通过预分区与自动分片实现水平扩展,是超大规模维表的理想载体。
选型建议:评估维表的数据规模、更新频率、查询模式(点查/范围查)与一致性要求。中小规模强一致场景选云原生关系库;极致低延迟小数据量选缓存;海量数据高吞吐选宽表库。
二、 结果表选型:高吞吐、可扩展的数据汇入终点
结果表是实时计算产出的最终存储目的地,用于下游分析、检索或服务调用。其选型需重点考虑写入吞吐量、存储成本、查询灵活性及与生态工具的集成。
- 云原生数据仓库:如 Snowflake、Amazon Redshift、Google BigQuery 或 阿里云 AnalyticDB。它们是实时计算结果进行交互式分析与报表的首选。支持高并发写入、PB级存储与复杂的SQL查询。通过存储计算分离、自动弹性与内置的压缩优化,在性能与成本间取得平衡。适合需要即席查询、多维度聚合的业务场景。
- 云原生消息队列与流存储:如 Apache Kafka(托管服务如 Confluent Cloud、MSK)或 Apache Pulsar。当计算结果需要被多个下游系统实时消费时,可将结果表建模为流(Stream)。此类服务提供高吞吐、低延迟的持久化消息队列,确保数据有序且不丢失,完美衔接实时计算与后续流处理链路。
- 云对象存储:如 Amazon S3、Google Cloud Storage 或 阿里云 OSS。对于数据湖架构,或计算结果主要用于低频批量分析、长期归档的场景,对象存储是成本极低的选项。实时计算引擎(如Flink)可直接以追加方式写入Parquet/ORC等列式格式文件,结合元数据服务(如 Hive Metastore)实现表分区管理。通过 Delta Lake、Apache Iceberg 等表格格式层,还能在对象存储上实现ACID事务与增量查询。
- 云原生搜索引擎:如 Elasticsearch(托管服务如 Amazon OpenSearch)或 阿里云 OpenSearch。当计算结果需要支持全文检索、复杂过滤或聚合分析时,可直接写入搜索引擎构建实时索引。它提供强大的查询能力与可视化支持,适合日志分析、监控告警、订单搜索等场景。
选型建议:根据数据使用目的选择。交互式分析选云数据仓库;多路实时分发选消息队列;低成本归档与分析选对象存储+表格格式;实时检索与可视化选搜索引擎。实践中常采用多路输出,将同一份结果写入不同存储以满足多样需求。
三、 核心实践原则
- 服务托管优先:优先选择全托管的云服务,避免运维负担,充分利用其弹性伸缩、高可用与备份恢复能力。
- 计算存储解耦:采用计算层(如Flink/Kafka Streams)与存储层分离的架构,使两者可独立扩展与优化。
- 成本与性能权衡:通过数据分层(热、温、冷)、选择合适的存储类型(如SSD/HDD)、利用自动压缩与分区策略优化成本。
- 生态集成顺畅:确保所选存储服务能与实时计算引擎(如Apache Flink)、数据开发平台及监控体系无缝集成。
- 可观测性与治理:建立结果表的数据血缘、质量监控与访问审计,保障数据资产的可管理性。
在云原生环境下,维表与结果表的选型已从单纯的技术组件选择,演进为对云上托管服务特性、成本模型及生态集成的综合考量。正确的选型能够为实时计算管道提供坚实的数据服务支撑,从而释放数据的实时价值。
如若转载,请注明出处:http://www.0meiyunhe.com/product/73.html
更新时间:2026-02-01 00:40:35